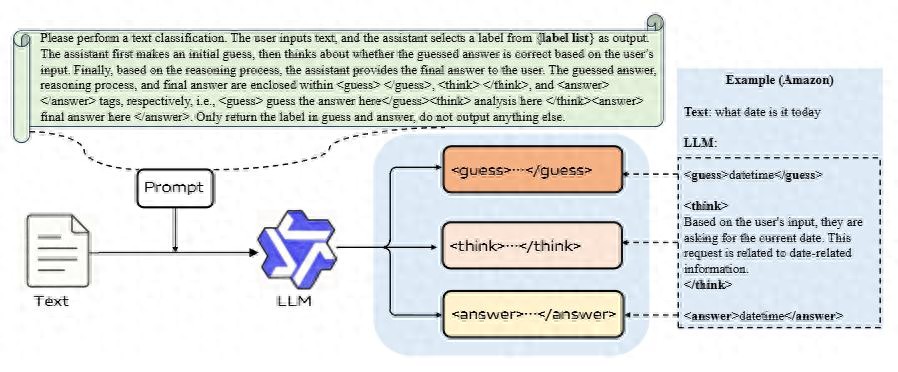


大模型的后训练阶段,很多人都纠结一个问题:到底是用 监督微调(SFT),还是 强化学习(RL)?SFT 简单高效,但能力上限不高;RL 能力强,但训练又慢又不稳。尤其是在 文本分类 这个场景,RL 表现一直不如人意。
vivo AI Lab 的研究团队试图打破这种两难局面。他们在近期被 EMNLP 2025 接收的论文中提出了一个新方法——GTA(Guess–Think–),试图把 SFT 和 RL 的优势融合起来:既要快,又要强。
![图片[1] | EMNLP 2025 接收!把“猜-思-答”三步走做成大模型训练新范式 | 星尘资源网](/wp-content/uploads/2025/10/1760376017369_0.jpg)
GTA 是什么?“先猜,再想,最后答”
GTA 的核心思想不复杂,甚至可以说挺“人类”的:
Guess(猜):模型先凭直觉给出一个初步猜测。这一步用标准的交叉熵损失训练,就像 SFT 一样,确保训练能快速收敛。Think(思):模型不是直接输出答案,而是对刚才的猜测进行“思考”——好不好?为啥对?为啥错?这一步让模型有机会反思,提高推理质量。(答):最终输出答案,这一步由 RL 来优化,不只是对不对,还包括整个答题过程的质量。
这个三阶段结构,相当于把 SFT 当“引路灯”,让 RL 不再盲目乱走;同时强化学习又能反过来提升最终结果的泛化能力。
![图片[2] | EMNLP 2025 接收!把“猜-思-答”三步走做成大模型训练新范式 | 星尘资源网](/wp-content/uploads/2025/10/1760376017369_1.jpg)
怎么防止“思路打架”?
SFT 和 RL 本质上是两种不同的训练目标,直接放在一起容易“打架”——你往东,我往西,模型就懵了。为了解决这个问题,作者设计了两个关键机制:
实验结果:SFT + RL,确实更香
GTA 在四个主流文本分类数据集上进行了实测,包括经典的情感分析数据集 SST-5、商品评论 、情绪识别 和新闻分类 BBC News。模型使用的是 Qwen2.5、Qwen3 和 LLaMA 的 3B 小模型,在 L40s 多机多卡集群上训练。
![图片[3] | EMNLP 2025 接收!把“猜-思-答”三步走做成大模型训练新范式 | 星尘资源网](/wp-content/uploads/2025/10/1760376017369_2.jpg)
实验对比了 SFT、GRPO(强化学习方法)和 GTA 三种方案:
简单说就是:GTA 既跑得快,又跑得远。
模型不是“跟着猜走”,而是“先猜后改”
有趣的是,虽然 GTA 里有“猜”这一步,但模型不会盲目跟着猜测走。论文展示了两个案例:
这说明“思考”这一步,的确在起作用——模型不是照单全收,而是在自我反省。
展望未来:不仅是分类
虽然目前 GTA 只在文本分类任务上做了验证,但从原理来看,它也可能适用于问答、摘要、对话生成等更复杂的 NLP 场景。作者也表示,未来会尝试在更大模型和更多任务上扩展 GTA。
当然,把 SFT 和 RL 融合,也确实带来更大的显存压力。为了控制成本,这次实验选择了 3B 级别的小模型。未来如果想在更大模型上用 GTA,还需要一些工程优化。
总结:GTA 是 SFT 和 RL 的“融合范式”
近年来,越来越多的研究都在探索如何把 SFT 和 RL 结合起来,比如通义的 CHORD、上海 AI 实验室的 LUFFY 等。vivo 提出的 GTA,是其中一个非常有代表性的实践。
它的思路不复杂,但效果扎实:用 SFT 引导 RL,用 RL 提升 SFT,中间加上一段“思考”过程,让模型逻辑更清晰、训练更稳健、表现更可靠。
一句话总结:SFT 给你速度,RL 给你高度,GTA 帮你两手都要。













请登录后查看评论内容