首页
视频
必备工具
项目推荐
项目陪跑
软件
电脑软件
手机软件
资源文章
技术文章
源码主题
进入论坛
搭建同款
发布
发布文章
创建话题
创建版块
发布帖子
开通会员
开通黄金会员
全站资源折扣购买
部分内容免费阅读
一对一技术指导
VIP用户专属QQ群
开通黄金会员
开通钻石会员
全站资源折扣购买
部分内容免费阅读
一对一技术指导
VIP用户专属QQ群
开通钻石会员
登录
注册
首页
视频
必备工具
项目推荐
项目陪跑
软件
电脑软件
手机软件
资源文章
技术文章
源码主题
进入论坛
搭建同款
开通会员 尊享会员权益
登录
注册
找回密码
GTA
共1篇
排序
更新
浏览
点赞
评论
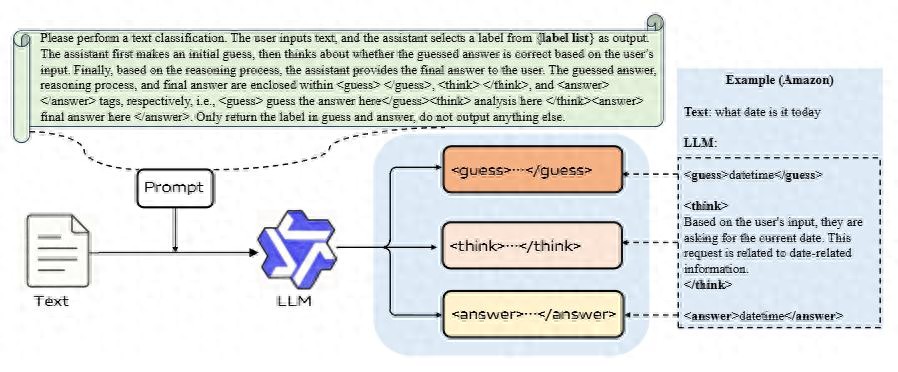
EMNLP 2025 接收!把“猜-思-答”三步走做成大模型训练新范式
大模型的后训练阶段,很多人都纠结一个问题:到底是用 监督微调(SFT),还是 强化学习(RL)?SFT 简单高效,但能力上限不高;RL 能力强,但训练又慢又不稳。
生活百科
站长
13天前
0
45
10
搭建同款网站
搭建和站长一样的网站
查看详情
在手机上浏览此页面
登录
没有账号?立即注册
用户名/手机号/邮箱
登录密码
记住登录
找回密码
登录
注册
已有账号,立即登录
设置用户名
邮箱
验证码
发送验证码
设置密码
注册
已阅读并同意
用户协议
主题模板推荐
欢迎访问星尘资源网
找项目,找教程,找工具,找资源就来星尘资源网
星尘资源网是一个专注分享实用的互联网技术教程,项目推荐,建站教程,AI 工具等内容的资源分享网站。帮助用户发现有趣且实用的资源。
星尘资源网
立即设置